论文链接
AlphaGo
AlphaGo使用了两个深度神经网络:一个是策略网络输出下一步落子位置的概率,一个是价值网络输出对位置的评估(也就是落子胜
率)
策略网络
通过有监督的学习来精确的预测高段位棋手的落子
再通过价值梯度增强学习来完成系统的增强
缩小高概率落子的搜索过程:使用价值网络(结合蒙特卡洛快速走子策略)在树上完成对落子位置的评估
价值网络
通过策略网络的自我博弈来预测游戏的胜方从而完成训练
训练结束之后,这两个网络通过蒙特卡洛树搜索的算法相结合来提供对未来局势的前望
AlphaGo Zero
特点
完全自学,超越人类
发展出超越人类认知的新知识,新策略
能够快速移植到新领域
与Alphago的不同
通过自我博弈增强学习来完成训练
没有任何的监督或者使用人工数据
使用棋盘上的黑白子作为输入特征
只使用一个神经网络,而不是分开的策略网络和价值网络
使用依赖于单一神经网络的简化版树搜索来评估落子概率和落子对局势的影响,不使用蒙特卡洛的方法
使用一种能在训练过程中完成前向搜索的增强学习算法
神经网络f(theta)
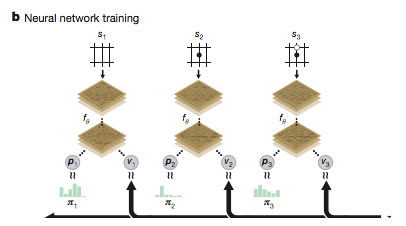
输入:位置、历史的原始图表
输出:移动概率值 (p,v)=f(theta)(S)
p:选择每个移动 a ,pa = Pr(a \| s)的概率
v:标量评估,估计当前玩家从位置s获胜的概率
神经网络f(theta)包括许多残差块的卷积层,批量归一化和整流器非线性(参见methods????)
自我训练

Alphago zero在每个位置St执行MCTS搜索(????)输出每次移动的概率 pai
MCTS搜索通常选择比f(theta)的原始移动概率p更强的移动(????)
使用改进的基于MCTS的策略来选择每个动作
使用游戏赢家z作为价值的样本,可以自我搜索 - 可以被视为强大的策略评估运算符(???)
强化学习算法的主要思想是使用这些搜索算子
S1-St是下棋的过程(这次走 黑棋,下次走白棋子,自我博弈???)在每个位置st中,使用最新的神经网络fθ执行MCTSαθ选择移动
在〜πt。终端位置sT根据游戏规则得分,以计算游戏赢家z