线性回归
网络流量分析
银行风险分析
基金股价预测
优化方法:梯度下降
初始点很重要
凸函数
一元连续可微函数在区间上是凸的,当且仅当函数位于所有它的切线的上方:对于区间内的所有x和y,都有f(y) ≥ f(x) + f '(x) (y − x)。特别地,如果f '(c) = 0,那么c是f(x)的最小值
一元可微函数在某个区间上是凸的,当且仅当它的导数在该区间上单调不减
一元二阶可微的函数在区间上是凸的,当且仅当它的二阶导数是非负的(二阶可微:二阶导数存在且连续)
凸函数的任何极小值也是最小值。严格凸函数最多有一个最小值
局限性
无法适应非线性数据
多目标学习
多目标学习,通过合并多个任务loss,一般能够产生比单个模型更好的效果
从线性到非线性
引入非线性激励(sigmod,relu等等)
非线性激励
选择标准:
对输入的调整,让输入数据经 过激励后有可比性**
反向梯度损失(在进行梯度下降时,不同layer学习的速度不同,导致梯度消失或者梯度爆炸)
tanh函数:数据映射到-1~1,缺点:x = 0 时,,没有了梯度输入
relu函数:正向截断负值,损失大量特征,反向梯度没有损失
Leaky relu :保留更多参数,少量梯度反向传播
神经元-神经网络
有没有线性回归的网络?
没有
神经网络为什么不是最后线性的?
因为每一层有非线性激励
神经网路的配件
损失函数 Loss
合适的损失函数能够使得深度学习模型收敛
Softmax??????

分类问题的预测结果更明显,收敛比较快
Corss entropy(交叉熵)??????
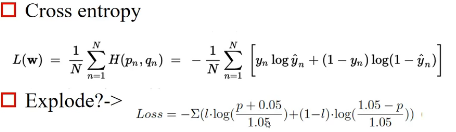
图中的0.05是为了防止函数爆炸
用途
目标为[0,1]区间的回归问题,以及生成图片等
loss函数的优化与设计

例如针对不同loss设计不同的weight,帮助某几项loss有更好的识别能力
比赛的话大多夺冠的是 使用各种RestNet,vgg,Google net等结合在一起,然后调整参数
比较狠的方法:刷库,很多个神经网络结合在一起,效果会很好,(比较吃机器)
学习率

1:固定的
2:不同的阶段,学习率不同
3:自适应的learning rate
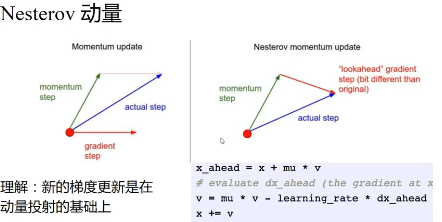
动量

调整动量和直接调大学习率的区别
方向不同,找的更准确
过拟合
应对(目标是是参数更均衡)-正则化

Dropout
参数过多,将其中一些参数置为0,随机置为0,某种程度上和Reguliazation效果很像
与Pooling的区别
Pooling的本质是降维,Dropout的本质是Regularization
Fine-tuning
找一个训练好的数据,model,只针对特定的一些layer进行update会有很好的效果
如果只是自己准备数据,然后开始从头训练会有很多问题
fcn(完全摒弃传统神经网络,全部使用卷积)